Report: Economic & Industrial Impact of “Attention Is All You Need” (Vaswani et al., 2017)
- Nov 2, 2025
- 5 min read
1. Thesis
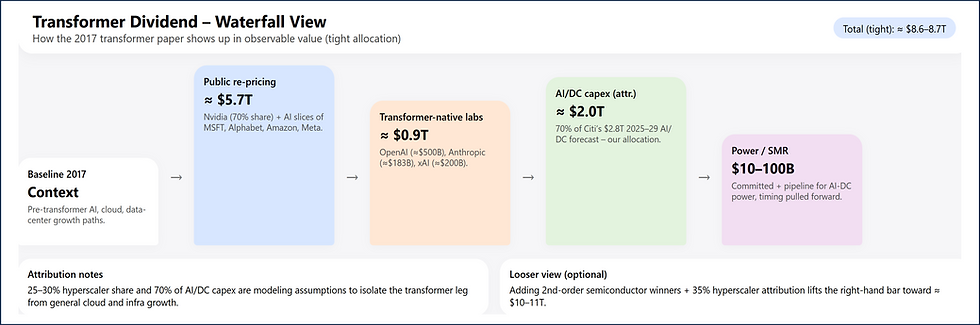
The 2017 transformer paper created a single, massively parallelizable architecture for sequence/language that (i) made scale itself a performance strategy, (ii) generated a compute-hungry workload that fit GPU roadmaps perfectly, and (iii) gave hyperscalers and new AI labs a board-level story to fund multi-trillion-dollar AI data centers. The measurable, observable part of this “transformer dividend” is about $8.6–8.7T today, and with modestly looser attribution it sits in the $10–11T band (Reuters, CompaniesMarketCap, Citi AI capex note, Sept 30 2025).
2. Public-market transformer dividend
2.1 Nvidia — strongest signal
Market cap Dec 2017: ≈$117–120B (CompaniesMarketCap, 2017 year-end).
Market cap Oct–Nov 2025: ≈$4.9–5.0T on AI/GPU demand (Reuters, Oct 29 2025).
Delta: ≈$4.8T.
Attributing 70% of that to transformer/LLM workloads (rest = gaming, auto, networking) gives ≈$3.3–3.4T that is reasonably tied to the transformer wave.
2.2 Hyperscalers that re-bent around transformers
Structured list:
Microsoft — 2017 ≈$0.61–0.66T → 2025 ≈$3.8–3.9T → Δ ≈$3.2T. Taking a conservative 25% as AI/transformer (Azure + OpenAI + Copilot) → ≈$0.8T (CompaniesMarketCap; 2024–25 earnings AI breakdowns).
Alphabet/Google — 2017 ≈$0.73T → 2025 ≈$3.3–3.4T → Δ ≈$2.6–2.7T. Taking 25% (Gemini, TPUs, DC build) → ≈$0.65–0.7T.
Amazon — 2017 ≈$0.56–0.58T → 2025 ≈$2.6T → Δ ≈$2.0T. Taking 25% (Bedrock, Q, Trainium/Inferentia, AI DCs) → ≈$0.5T.
Meta — 2017 ≈$0.51T → 2025 ≈$1.6–1.7T → Δ ≈$1.1–1.2T. Taking 30% (AI ranking, gen-AI, LLaMA) → ≈$0.33–0.35T.
2.3 Public subtotal
Nvidia transformer share: ≈$3.4T.
Four-hyperscaler transformer slices: ≈$2.3T.
Public, clearly defensible: ≈$5.7T.
3. Transformer-native / model-lab platforms
Structured list:
OpenAI — secondary/share sale at ≈$500B valuation (FT, Reuters, Oct 2025).
Anthropic — Sept 2025 raise leading to ≈$183B post-money (company blog, Reuters, Axios Sept 2025).
xAI — Sept 2025 funding implying ≈$200B valuation (Reuters, TechCrunch/Forbes coverage).
Subtotal, visible transformer-native platforms: ≈$0.88–0.9T.
(If we added Mistral, Cohere, Perplexity, Character.AI at 2025 marks, this bucket would go over $1T, but the above three are already enough to show the order of magnitude.)
4. Infrastructure, capex, and power knock-on
4.1 AI/DC capex
Citi (Sept 30 2025) projected ≈$2.8T AI infrastructure spending through 2029, driven by ~55 GW of new AI power capacity.
If we attribute 70% of that to transformer-style LLMs (the part that needs parallel attention, fast training, large context windows), we get ≈$2.0T of capex that shows up in this form because transformers scaled.
4.2 Nuclear / SMR response
2025 reporting across Reuters, IAEA bulletins, U.S. SMR filings shows >$10B already committed or LOI’d by techs/utilities for SMR/advanced nuclear explicitly to power DC/AI growth (Google-TVA, Amazon SMR plans, Meta/Microsoft scoping).
Identified pipeline is ≈22 GW of SMR projects framed around data-center/AI loads → ≈$60–100B potential given usual SMR $/kW.
5. Investment flow around the paradigm
Stanford AI Index for 2025 pegs 2024 global private AI investment at ≈$252B, of which GenAI ≈$33.9B.
H1 2025 GenAI alone is >$49B, i.e. 2025 will outrun 2024 on GenAI.
Rolling up 2018–25 foundation-model / LLM / platform rounds → ≈$300–500B actually deployed that explicitly assumes “transformer-like models keep scaling.”
6. Roll-up (observed, conservative)
Public-market repricing tied to transformers: ≈$5.7T.
Transformer-native private platforms: ≈$0.9T.
Transformer-caused AI/DC capex (attributed share): ≈$2.0T.
Energy / SMR for AI: $0.01–0.1T.
Conservative, observable total: ≈$8.6–8.7T.
With modestly looser attribution (e.g. 35% of hyperscaler delta, add obvious second-order semiconductor winners such as TSMC, ASML, Broadcom, AMD, and AI-PC/DC real-estate uplift): ≈$10–11T.
7. Attribution and caveats
2017 was not a vacuum — attention, seq2seq, ConvS2S, scaling-law work were already in flight.
Part of the $2.8T capex is clearly optionality and can slip if AI monetization lags.
Some large beneficiaries (Apple, wider chip toolchain, DC real-estate) are not counted here to keep the core claim clean.
8. Transformer dividend vs counterfactual 2017 (“slower / much slower”)
This section answers: what specifically arrived early or at a bigger scale because the 2017 paper made transformers the default?
8.1 What actually happened (with-transformer)
GPU re-rating in 7–8 years, not 12–15 — Nvidia from ≈$120B (2017) to ≈$5T (2025) on transformer/LLM demand.
Foundation-model natives at ≈$0.9T by 2025 — OpenAI ≈$500B, Anthropic ≈$183B, xAI ≈$200B.
Hyperscaler green-lights for ≈$2.8T AI/DC capex by 2029 — large, power-hungry LLMs became the accepted future workload.
Nuclear/SMR moved from “later in the decade” to “we’re signing now” — because AI/DC loads made 2030 power gaps explicit.
8.2 Counterfactual 2017 (no transformer flashpoint)
Assumptions:
Attention remains niche; RNN/seq2seq and task-specific architectures continue.
Scaling is worse, training is slower, per-token cost is higher, so useful models are smaller and arrive later.
Then the following go slower:
Nvidia
Still wins accelerators for vision, AV, HPC; could plausibly 5–7× from 2017 levels to ≈$0.8–1.0T by mid-2020s on “ordinary AI + gaming + autos.”
What we actually saw is ≈$5T.
Brought-forward / transformer value on Nvidia alone = $5T − $1T ≈ $4T. Even with a 50% haircut (“something transformer-like would’ve appeared by 2019”), there is still ≈$2T of value that exists earlier and bigger because of the 2017 paper.
Hyperscaler AI/DC capex
Without transformers, AI stays a feature of cloud, not the reason to double DC build-out.
Citi’s ≈$2.8T by 2029 would look more like ≈$0.8–1.2T stretched over more years.
Brought-forward capex: ≈$1T.
Model-lab valuations
In a non-transformer 2017, labs look like large applied-ML/RL shops → $10–50B scale, not $183B or $500B.
Transformer dividend here ≈$0.8T (= $0.9T actual − say $0.1T baseline).
Nuclear/SMR
Without AI/DC urgency, SMRs stay in utility/defense/remotes → 2030s, not 2025–26 pilots.
The $10B+ committed and $60–100B pipeline is mainly a timing pull-forward.
Financing velocity
2024’s $252B AI private and 2025’s $49B+ GenAI H1 rely on “these models keep scaling.”
In the counterfactual, that run-rate is probably half and spread across more traditional ML/analytics.
8.3 Quantifying the brought-forward part
Structured list:
Nvidia brought-forward value: ≈$2–4T.
Capex brought forward: ≈$1T.
Model-lab super-valuations: ≈$0.8T.
Power/SMR timing value: ≈$10–100B.
Financing velocity: ≈$0.1–0.2T.
This implies that ≈$4–6T of what we see in 2025 is not just “caused” by transformers but “made to happen earlier and bigger” by the 2017 paper. In other words, about half of the observed transformer dividend is acceleration.
9. Why this framing matters
It lets boards and strategy teams say: “Even if another architecture had emerged, we would have seen ½–⅔ of today’s AI value — the rest is because transformers were simple, parallel and early (2017).”
It also identifies which budgets get cut first if AI monetization lags: the brought-forward part (≈$1T capex, frontier-lab premiums) is the most at risk.
10. Summary
Observed, conservative transformer-driven value:
Public-market repricing tied to transformers (Nvidia + AI slices of MSFT, Alphabet, Amazon, Meta): ≈$5.7T.
Transformer-native labs (OpenAI ≈$500B; Anthropic ≈$183B; xAI ≈$200B): ≈$0.9T.
AI/DC capex that exists in this form because transformers scaled (Citi 2025, 55 GW, $2.8T → 70% attribution): ≈$2.0T.
Energy / SMR tied to AI DCs (committed + pipeline): $0.01–0.1T.
Subtotal (tight): ≈$8.6–8.7T.
Reasonable upper band:
Loosen hyperscaler attribution to 35%,
Add second-order semiconductor winners and DC-adjacent winners,
Keep AI/DC capex at $2.0T,
→ Total sits in: ≈$10–11T.
Acceleration vs counterfactual 2017:
Nvidia brought-forward value: ≈$2–4T.
Capex brought-forward: ≈$1T.
Lab super-valuations vs “big applied ML labs”: ≈$0.8T.
Power/SMR timing value: ≈$10–100B.
→ Acceleration component: ≈$4–6T (i.e. about half of what we see).
Therefore: even after giving credit to pre-2017 work, the 2017 transformer paper is plausibly a $10T-class event for the tech/AI/infra stack, with $4–6T of that being “we got there earlier and at bigger scale than we otherwise would have.”
Arindam Banerji, PhD



Comments